Quickly build and deploy LLMs with Retrieval Augmented Generation, featuring Intel Accelerators and Azure - Seguridad Mania.com - España y América Latina
Portal sobre tecnologías para la seguridad física
Estás en »Webinars
Estás en »Webinars
Martes 28 de Ene, 2025
RAG offers a new way to maximize the capabilities of large language models (LLMs) to produce more accurate, context-aware, and informative responses. Join Akash Shankaran (Intel), Ron Abellera (Microsoft), and Juan Pablo Norena (Canonical) for a tutorial on how RAG can enhance your LLMs. The session will explore how to optimize LLMs with RAG using Charmed OpenSearch, which can serve multiple services like data ingestion, model ingestion, vector database, retrieval and ranking, and LLM connector. We will also show the architecture of our RAG deployment in Microsoft® Azure Cloud. Notably, the vector search capabilities of RAG are enhanced by Intel AVX® Acceleration, delivering faster processing and high-throughput performance for the RAG workflow.
05:30 - 06:00 hs GMT+1
06:00 - 07:00 hs GMT+1
04:00 - 05:00 hs GMT+1
05:00 - 06:00 hs GMT+1
06:00 - 07:00 hs GMT+1
09:00 - 10:00 hs GMT+1
16:00 - 17:00 hs GMT+1
00:00 - 01:00 hs GMT+1
04:30 - 05:00 hs GMT+1
01:00 - 02:00 hs GMT+1
02:00 - 03:00 hs GMT+1
03:00 - 04:00 hs GMT+1
05:00 - 06:00 hs GMT+1
11:30 - 12:00 hs GMT+1
13:00 - 14:00 hs GMT+1
00:00 - 01:00 hs GMT+1
03:00 - 04:00 hs GMT+1
03:00 - 04:00 hs GMT+1
04:30 - 05:00 hs GMT+1
03:00 - 04:00 hs GMT+1
06:00 - 07:00 hs GMT+1
10:00 - 11:00 hs GMT+1
13:00 - 14:00 hs GMT+1
00:00 - 01:00 hs GMT+1
03:00 - 04:00 hs GMT+1
01:00 - 02:00 hs GMT+1
05:00 - 06:00 hs GMT+1
02:00 - 03:00 hs GMT+1
03:00 - 04:00 hs GMT+1
11:30 - 12:00 hs GMT+1
13:00 - 14:00 hs GMT+1
11:00 - 12:00 hs GMT+1
00:00 - 01:00 hs GMT+1
06:00 - 07:00 hs GMT+1
05:00 - 06:00 hs GMT+1
09:00 - 10:00 hs GMT+1
05:30 - 06:00 hs GMT+1
06:00 - 07:00 hs GMT+1
04:00 - 05:00 hs GMT+1
05:00 - 06:00 hs GMT+1
06:00 - 07:00 hs GMT+1
09:00 - 10:00 hs GMT+1

La Autoridad Portuaria de la Bahía de Algeciras (APBA) ha instalado cámaras térmicas en las zonas de mayor tránsito de pasajeros del puerto para controlar la temperatura corporal de los pasajeros sin necesidad de pararles. ... Leer más ►
Publicado el 2-Jul-2020 • 14.23hs
Publicado el 25-Ene-2017 • 19.27hs
Publicado el 20-Ene-2017 • 13.11hs
![Ciberseguridad en la gran empresa según el CIO de Vocento [Webinar de 6o min]](https://www.seguridadmania.com/img/articles/71622/vocento.png)
Publicamos grabación de webinar que tuvo lugar el pasado 28/03/2019 por el CIO del Grupo de Medios de Comunicación español Vocento Jorge Oteo en el que explica su visión de la Ciberseguridad hoy. ... Leer más ►
Publicado el 29-Mar-2019 • 10.12hs
Publicado el 20-Jun-2018 • 11.21hs
Publicado el 31-May-2018 • 10.21hs
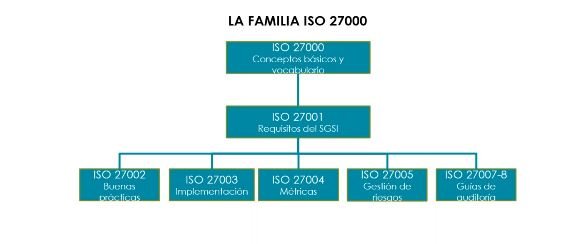
... Leer más ►
Publicado el 23-Jun-2020 • 16.05hs
Publicado el 26-Set-2019 • 10.36hs
Publicado el 26-Mar-2019 • 12.09hs
Publicado el 11-Oct-2016 • 12.48hs
Publicado el 15-Mar-2016 • 11.59hs
Publicado el 2-Feb-2017 • 11.38hs
Publicado el 20-Jun-2014 • 17.17hs
Publicado el 31-May-2011 • 05.13hs
Publicado el 25-Set-2008 • 17.54hs
Publicado el 1-Set-2016 • 16.11hs
Publicado el 31-Ago-2016 • 18.53hs
Publicado el 19-Ene-2017 • 15.47hs
Publicado el 4-Jul-2016 • 18.51hs