Building a Big Data Stack on Kubernetes - Seguridad Mania.com - España y América Latina
Portal sobre tecnologías para la seguridad física
Estás en »Webinars
Estás en »Webinars
Jueves 25 de Ene, 2018
There is growing interest in running Apache Spark natively on Kubernetes (see https://github.com/apache-spark-on-k8s/spark). Intended for software engineers, developers, architects and technical leads who develop Spark applications, this session will discuss how to build a big data stack on Kubernetes. In particular, it will show how Spark scheduler can still provide HDFS data locality on Kubernetes by discovering the mapping of Kubernetes containers to physical nodes to HDFS datanode daemons. You’ll also learn how you can provide Spark with the high availability of the critical HDFS namenode service when running HDFS in Kubernetes.
06:00 - 07:00 hs GMT+1
11:00 - 12:00 hs GMT+1
04:00 - 05:00 hs GMT+1
05:00 - 06:00 hs GMT+1
06:00 - 07:00 hs GMT+1
09:00 - 10:00 hs GMT+1
16:00 - 17:00 hs GMT+1
00:00 - 01:00 hs GMT+1
04:30 - 05:00 hs GMT+1
01:00 - 02:00 hs GMT+1
02:00 - 03:00 hs GMT+1
03:00 - 04:00 hs GMT+1
05:00 - 06:00 hs GMT+1
11:30 - 12:00 hs GMT+1
13:00 - 14:00 hs GMT+1
00:00 - 01:00 hs GMT+1
03:00 - 04:00 hs GMT+1
03:00 - 04:00 hs GMT+1
04:30 - 05:00 hs GMT+1
03:00 - 04:00 hs GMT+1
06:00 - 07:00 hs GMT+1
13:00 - 14:00 hs GMT+1
03:00 - 04:00 hs GMT+1
03:30 - 04:00 hs GMT+1
01:00 - 02:00 hs GMT+1
05:00 - 06:00 hs GMT+1
02:00 - 03:00 hs GMT+1
03:00 - 04:00 hs GMT+1
13:00 - 14:00 hs GMT+1
06:00 - 07:00 hs GMT+1
09:00 - 10:00 hs GMT+1
05:00 - 06:00 hs GMT+1
09:00 - 10:00 hs GMT+1
06:00 - 07:00 hs GMT+1
11:00 - 12:00 hs GMT+1
04:00 - 05:00 hs GMT+1
05:00 - 06:00 hs GMT+1
06:00 - 07:00 hs GMT+1
09:00 - 10:00 hs GMT+1

La Autoridad Portuaria de la Bahía de Algeciras (APBA) ha instalado cámaras térmicas en las zonas de mayor tránsito de pasajeros del puerto para controlar la temperatura corporal de los pasajeros sin necesidad de pararles. ... Leer más ►
Publicado el 2-Jul-2020 • 14.23hs
Publicado el 25-Ene-2017 • 19.27hs
Publicado el 20-Ene-2017 • 13.11hs
![Ciberseguridad en la gran empresa según el CIO de Vocento [Webinar de 6o min]](https://www.seguridadmania.com/img/articles/71622/vocento.png)
Publicamos grabación de webinar que tuvo lugar el pasado 28/03/2019 por el CIO del Grupo de Medios de Comunicación español Vocento Jorge Oteo en el que explica su visión de la Ciberseguridad hoy. ... Leer más ►
Publicado el 29-Mar-2019 • 10.12hs
Publicado el 20-Jun-2018 • 11.21hs
Publicado el 31-May-2018 • 10.21hs
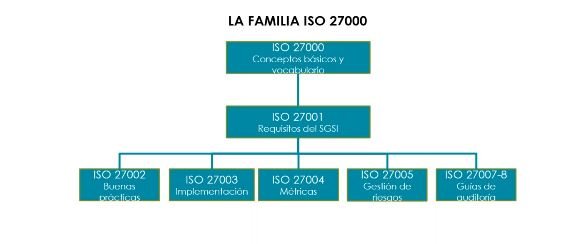
... Leer más ►
Publicado el 23-Jun-2020 • 16.05hs
Publicado el 26-Set-2019 • 10.36hs
Publicado el 26-Mar-2019 • 12.09hs
Publicado el 11-Oct-2016 • 12.48hs
Publicado el 15-Mar-2016 • 11.59hs
Publicado el 2-Feb-2017 • 11.38hs
Publicado el 20-Jun-2014 • 17.17hs
Publicado el 31-May-2011 • 05.13hs
Publicado el 25-Set-2008 • 17.54hs
Publicado el 1-Set-2016 • 16.11hs
Publicado el 31-Ago-2016 • 18.53hs
Publicado el 19-Ene-2017 • 15.47hs
Publicado el 4-Jul-2016 • 18.51hs